Research
My main interests lie in Applied & Computational Mathematics with focus on Scientific Machine Learning, Inverse Problems & Uncertainty Quantification.
I am interested in applying computational mathematics and machine learning in all sciences. I am interested in giving Machine learning in science a solid theoretical foundation and transform it in a proper scientific tool. I work in various fields, since my interest is more on the methodologies than in the applications. I have published in fields as physics, medicine, food technologies, statistics and mathematics.
In this page you will find a short overview of some of my research project, that I hope will give you an idea about the research questions I am interested in.
General Overview
My main interests lie in Applied & Computational Mathematics with focus on Scientific Machine Learning, Inverse Problems & Uncertainty Quantification.
Inverse problems & scientific estimation (recover latent scientific quantities from indirect/noisy measurements; study identifiability, stability, and consistency, with spectroscopy, sensing, medical/remote imaging as testbeds).
Uncertainty quantification for reliable ML.
Metrics and validation approaches that explicitly incorporate label/measurement noise; bootstrap and related tools for realistic performance assessment.
Fundamental limits & model-agnostic bounds.
Algorithms to estimate Bayes error / intrinsic task difficulty.
Learning in function spaces (Learning & Statistics in Infinite-Dimensional Spaces).
Operator/function-valued learning and generalization on spectra, curves, and fields.
Structure- and domain-informed ML (explainability with physics/chemistry priors).
Domain adaptation and interpretable models that map spectral features to physico-chemical mechanisms; small-datasets.
Scientific sensing & instrumentation with ML (ML-enhanced, often multitask, sensors; super-resolution for fast spectroscopy; end-to-end design and analysis).
Open benchmarks/datasets for satellite vision and medical imaging to make evaluation reproducible and failure modes visible.
Operator learning and regression on function spaces, approximation and generalization rates, and sample-complexity for scientific tasks.
Effects of label/input/algorithmic noise and model misspecification; design of estimators and training schemes that are stable to perturbations and measurement error.
Functional Theory and Random Matrix Theory and their relations to the mathematical foundations of machine learning.
Computational astrophysics. I have an on-going cooperation with INAF (Istituto Nazionale Astrofisica, Italy) in Bologna and Milano. Projects are on scientifically informed algorithm development, uncertainty and error estimation of deep learning algorithms applied to astrophysics, spectral model-agnostic feature extraction, etc.
Computational food technology. I am working on algorithms to extract chemical information from various food types (as maize, olive oil, wine, etc.) from optical measurements, in particular fluorescence and Raman spectroscopy (in collaboration with Prof. Dr. Venturini). I am also interested in developing explainable ML approaches, to study if algorithms really learns from the chemistry of the samples, or from other aspects that are not related to physics or chemistry.
Some Examples…
Scientifically Informed Algorithm Development
In collaboration with INAF (Istituto Nazionale di Astrofisica, Italy) in Bologna and Prof. Francesca Venturini in Zürich, we are developing novel variations of clustering algorithms that incorporate scientific knowledge and domain-specific principles. Our current work focuses on guided clustering techniques that uses seed points and centroids, strategically chosen based on the underlying physics of the data, to inform and constrain the clustering process from the outset. This approach has already led to the development of a usable Python package called CLiMB (Clustering in Multiphase Boundaries) (GitHub Link). Several papers applying these methods to real-world datasets are currently in preparation.
Features of the Python Library (Lorenzo Monti)
Two-Phase Clustering: Combines constrained clustering with exploratory clustering to identify both known and novel patterns.
Density-Aware: Uses local density estimation to intelligently filter and assign points.
Flexible Exploratory Phase: Supports multiple clustering algorithms (DBSCAN, HDBSCAN, OPTICS) through a strategy pattern.
Visualization Tools: Built-in 2D and 3D visualization capabilities for cluster analysis.
Parameter Tuning: Builder pattern for flexible parameter adjustment.
Customizable Distance Metrics: Now supports various distance metrics such as Euclidean, Mahalanobis, and custom metrics, offering greater flexibility in distance calculation.
Advanced Seed Points: Ability to initialize clustering with known seed points provided in a dictionary structure, allowing for more precise control over centroid initialization.
In general I am interested in transforming “dumb” machine learning algorithms, in something that can be used to understand the physics or chemistry of phenomena. One of my goal is to move away from a black-box approach, and transform machine learning algorithms in “scientific instruments” with an associated error that can be used in disproving or supporting scientific hypotheses.
Estimation of Machine Learning model errors in worst case scenarios
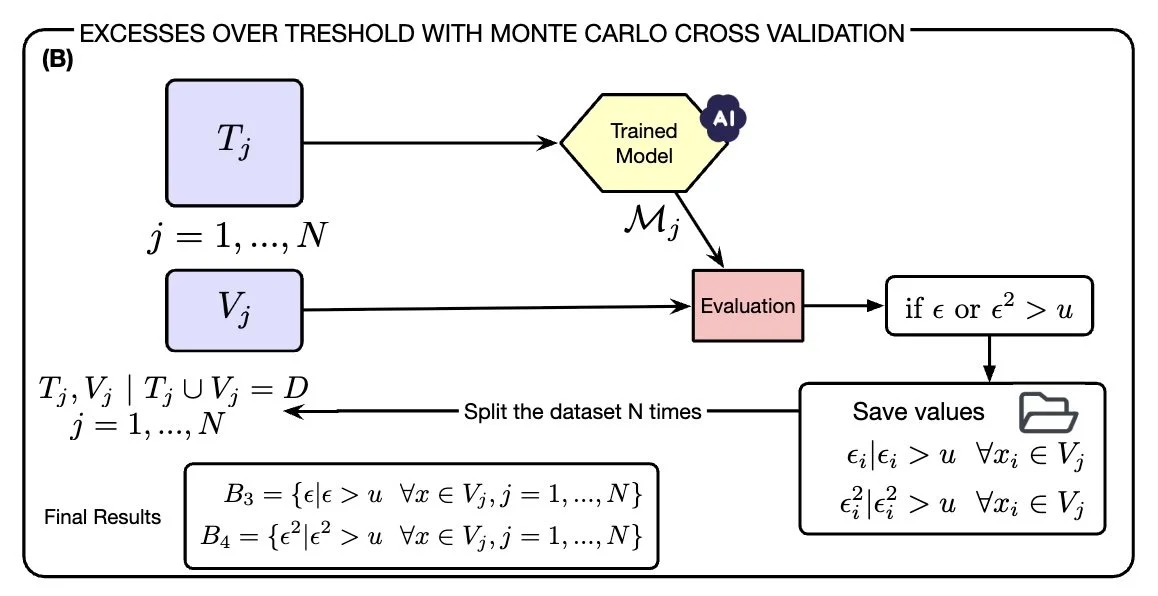
We developed, together with Prof. Dr. Venturini, a new framework that allows a stasticial analysis of model errors (preprint: https://arxiv.org/abs/2503.24262). In this work, we present a new statistical framework based on Extreme Value Theory (EVT) to overcome a major limitation in standard machine learning validation techniques, their inability to quantify extreme, worst-case errors. This is particularly important in high-stakes domains such as healthcare, finance, and public policy, where rare but large prediction errors can have serious consequences. While traditional metrics like MSE or MAE focus on average performance, our EVT-based method provides a statistically grounded approach to estimating the probability and scale of rare prediction failures. We demonstrate how our approach can be combined with Monte Carlo cross-validation and validate it on both synthetic and real-world datasets (including the Diabetes and WHO Life Expectancy datasets).


Images reproduced from Michelucci, U., & Venturini, F. (2024). Deep learning domain adaptation to understand physico-chemical processes from fluorescence spectroscopy small datasets and application to the oxidation of olive oil. Scientific Reports, 14(1), 22291.
Our results show that EVT enables a more realistic and risk-aware assessment of model performance, exposing vulnerabilities that conventional methods often miss. We believe this approach can help build more trustworthy AI systems, especially in critical applications where understanding and managing extreme outcomes is essential. Together with INAF (Istituto Nazionale Astrofisica, Italy) in Bologna we are applying this method on metallicity measurements of RR Lyrae stars from the Gaia Data Release 3 catalogue, and other datasets.
Deep Learning Applied to Spectra (1D and 2D) (in various applications of Spectroscopy)
Applying deep learning (and in general machine learning) to spectra (in 1D and 2D) poses difficult challenges. In several projects I am working in developing new methods for various purposes.
Do spectral bands feature selection in spectra, considering the problem that spectral intensities that are close in wavelength are strongly correlated and thus poses a challenge to traditional feature selection methods. This has led me to study and develop methods that include genetic algorithms to allow for flexible selection of relevant wavelengths.
I am studying intensely the role of noise (for example of white noise) in spectra, and how its presence (or absence) will make algorithms to completely ignore physical features as peaks. In particular I am interested in the behaviour of algorithms with inputs with a high dimensionalty, and in the theory of the behaviour of algorithms in the limit for dimensions to infinity.
I am studying this in various projects: from food technology (with Prof. Dr. Venturini), to astrophysics (with the INAF in Milano).
Machine Learning in Food Technology
We have worked a lot with Prof. Dr. Venturini in various application of machine learning to food technology.
Our projects in the area involve olive oil, wine and toxin contamination in various foods.
One of the main challenges for olive oil producers is the ability to assess oil quality regularly during the production cycle. The quality of olive oil is evaluated through a series of parameters that can be determined, up to now, only through multiple chemical analysis techniques. This requires samples to be sent to approved laboratories, making the quality control an expensive, time-consuming process, that cannot be performed regularly and cannot guarantee the quality of oil up to the point it reaches the consumer. Our papers present new approaches that are fast and based on low-cost instrumentation, and which can be easily performed in the field.
The proposed methods are based on fluorescence spectroscopy and, between other algorithms, one-dimensional convolutional neural networks and allow to predict five chemical quality indicators of olive oil (acidity, peroxide value, UV spectroscopic parameters K270 and K232, and ethyl esters) from one single fluorescence spectrum obtained with a very fast measurement from a low-cost portable fluorescence sensor. The results indicate that the proposed approaches gives exceptional results for quality determination through the extraction of the relevant physicochemical parameters. This would make the continuous quality control of olive oil during and after the entire production cycle a reality.
Some papers in this field we published over the years are:
Smeesters, Lien, Francesca Venturini, Stefan Paulus, Anne-Katrin Mahlein, David Perpetuini, Daniela Cardone, Arcangelo Merla et al. "2025 photonics for agrifood roadmap: towards a sustainable and healthier planet." Journal of Physics: Photonics (2025).
Michelucci, U., & Venturini, F. (2024). Deep learning domain adaptation to understand physico-chemical processes from fluorescence spectroscopy small datasets and application to the oxidation of olive oil. Scientific Reports, 14(1), 22291.
Gucciardi, A., El Ghazouali, S., Michelucci, U., & Venturini, F. (2024, June). Machine learning feature extraction for predicting the ageing of olive oil. In Data Science for Photonics and Biophotonics (Vol. 13011, pp. 74-82). SPIE.
Venturini, F., Sperti, M., Michelucci, U., Gucciardi, A., Martos, V. M., & Deriu, M. A. (2023). Extraction of physicochemical properties from the fluorescence spectrum with 1D convolutional neural networks: Application to olive oil. Journal of Food Engineering, 336, 111198.
Venturini, F., Michelucci, U., Sperti, M., Gucciardi, A., & Deriu, M. A. (2022, May). One-dimensional convolutional neural networks design for fluorescence spectroscopy with prior knowledge: Explainability techniques applied to olive oil fluorescence spectra. In Optical Sensing and Detection VII (Vol. 12139, pp. 326-333). SPIE.
Venturini, F., Sperti, M., Michelucci, U., Herzig, I., Baumgartner, M., Caballero, J. P., ... & Deriu, M. A. (2021). Exploration of Spanish olive oil quality with a miniaturized low-cost fluorescence sensor and machine learning techniques. Foods, 10(5), 1010.
Philosophy of Science
I dedicate a special section to Philosophy of Science, a special passion of mine. I have an insatiable need to understand how AI fits into the science paradigm. Is AI only a tool, or is something more? How can we do science with AI? How does it fit in philosophy of science? Is really an example of inductivism, as described by Bacon? Can we use as a falsification tool, as described by Popper? All those questions are not answered but are fundamental in understanding the role that AI will have in our society in the future.
An example of why this is important is the question if algorithms that allow facial recognition can be free of bias, or if this is a fundamental part of algorithms. How to decide what algorithm is scientific and which one is not (due to the strong stochastic nature of machine learning)? What role plays reproducibility in the use of AI, since the results have a strong statistical nature?